lambdarepresentation.github.io
A State Representation for Diminishing Rewards
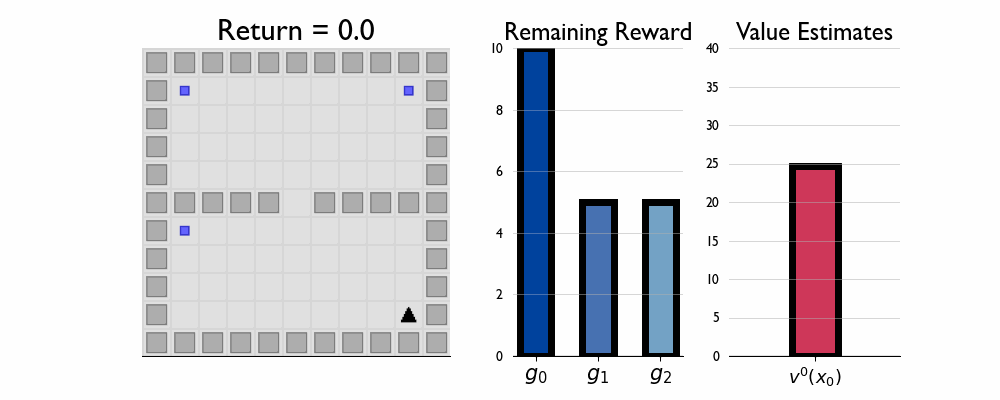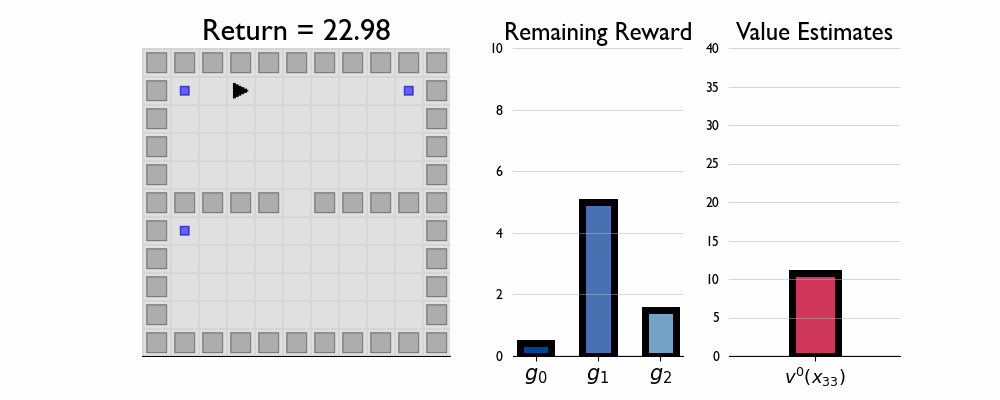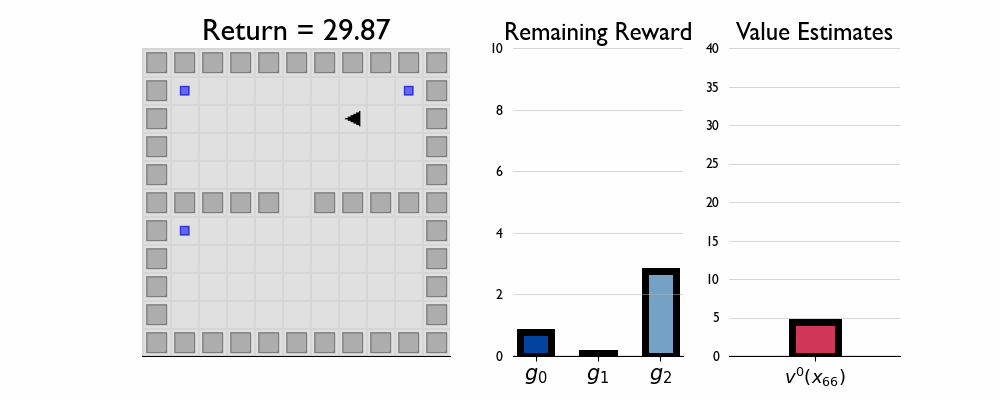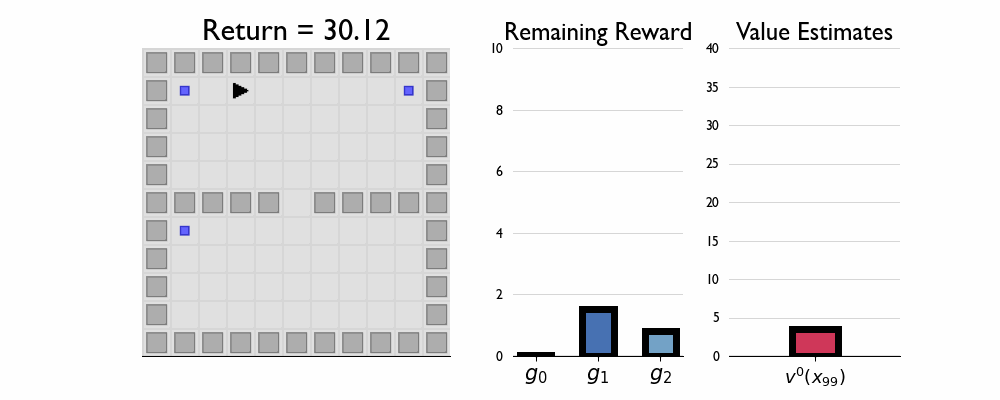
Here we present GIFs of agents trained using the λR across several navigation domains. A consistent theme is that accurate policy evaluation using the ``correct’’ λ leads to stronger performance. Using a λ which is too high typically leads to overstaying at reward locations, while a λ which is too low leads the agent to abandon rewarded locations too early.
Policy Learning in TwoRooms
In this this setting the true λ is 0.5.
Agent λ = 0.5:
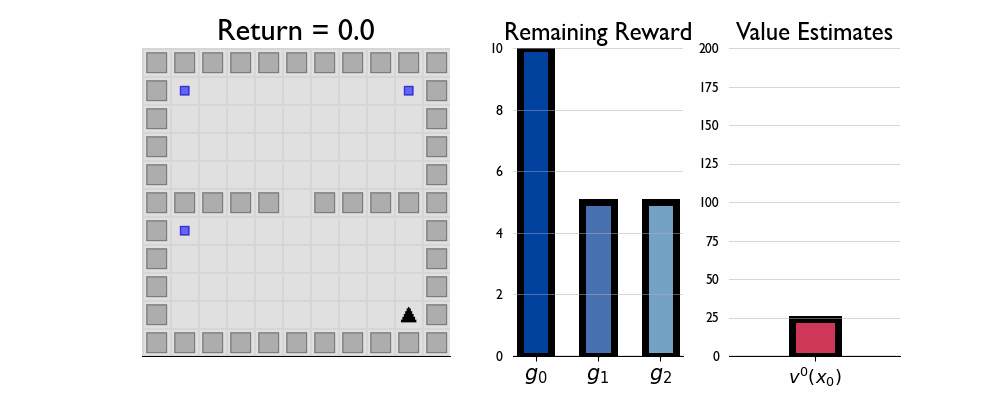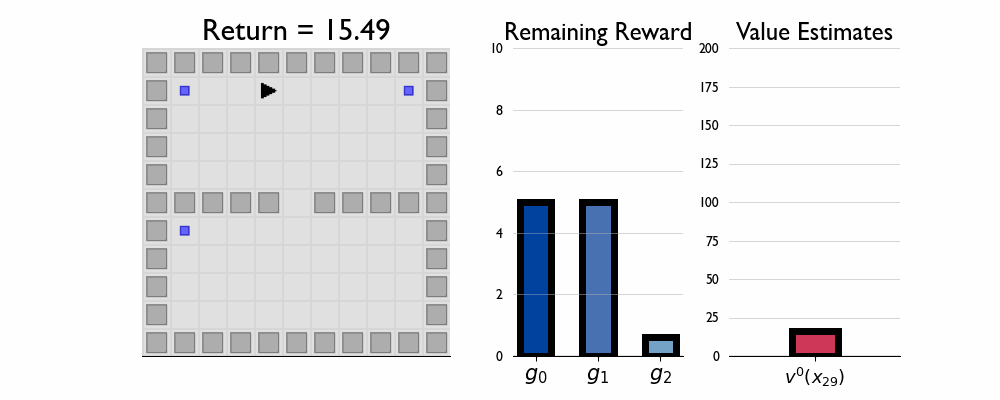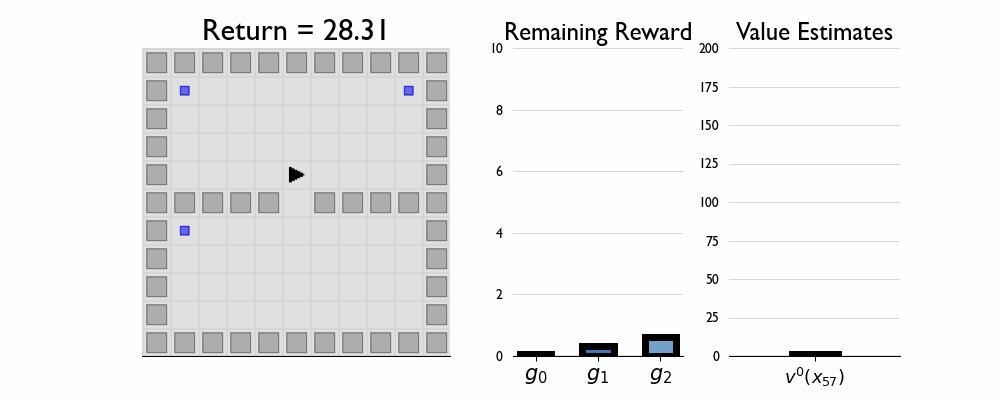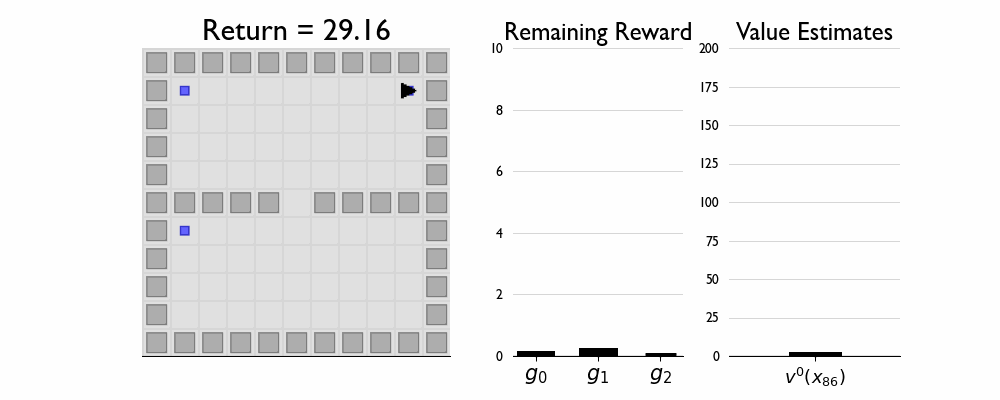
Agent λ = 0.0:
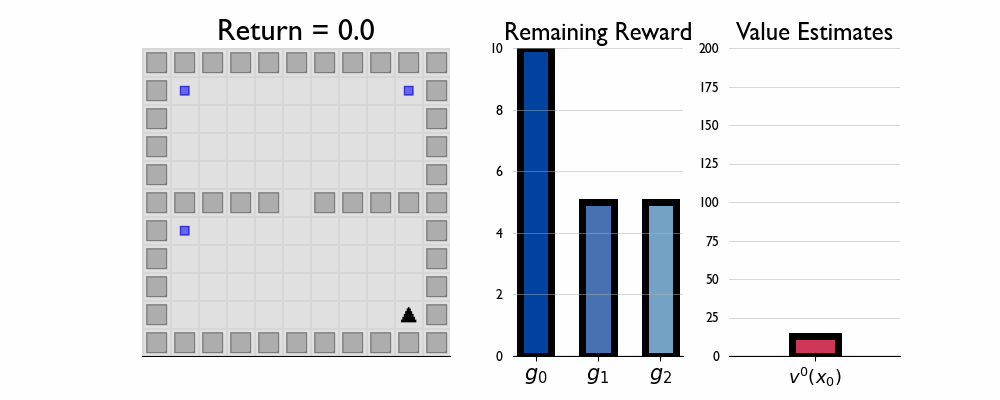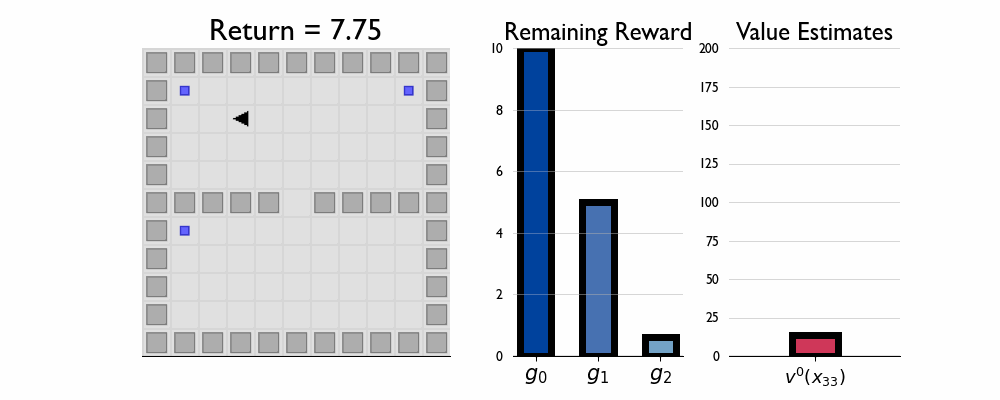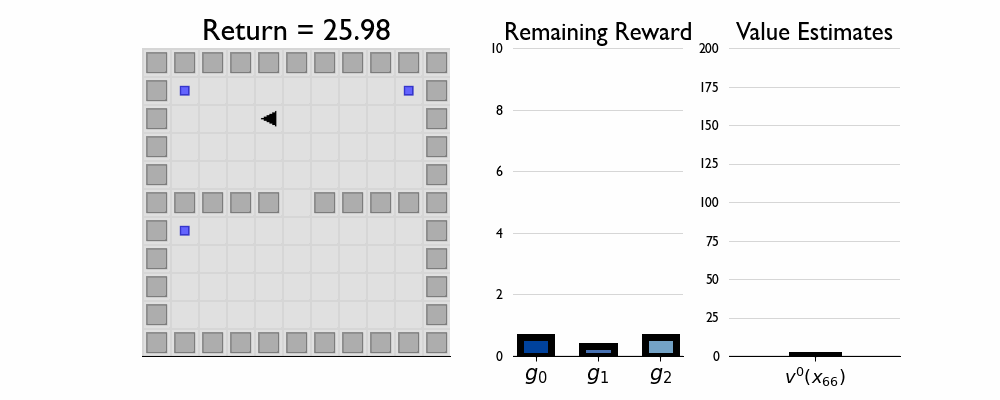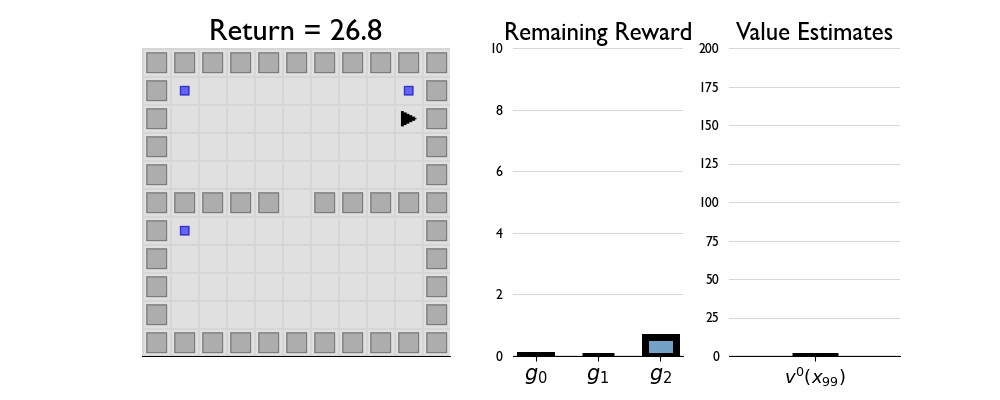
Agent λ = 1.0:
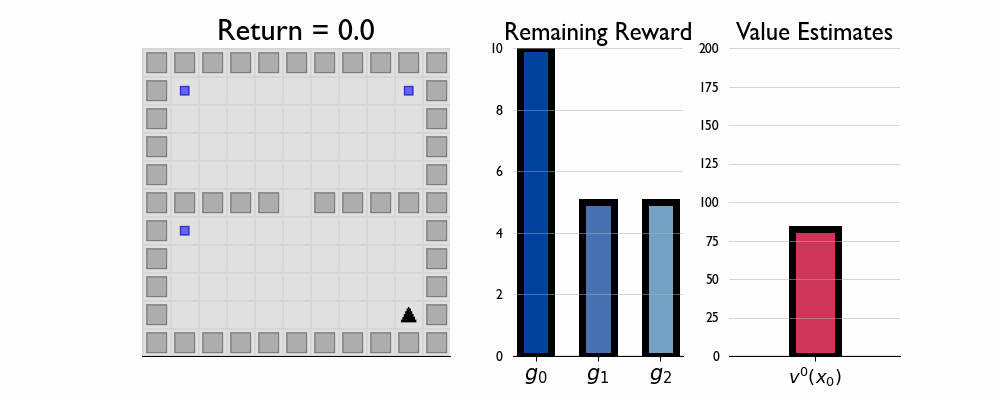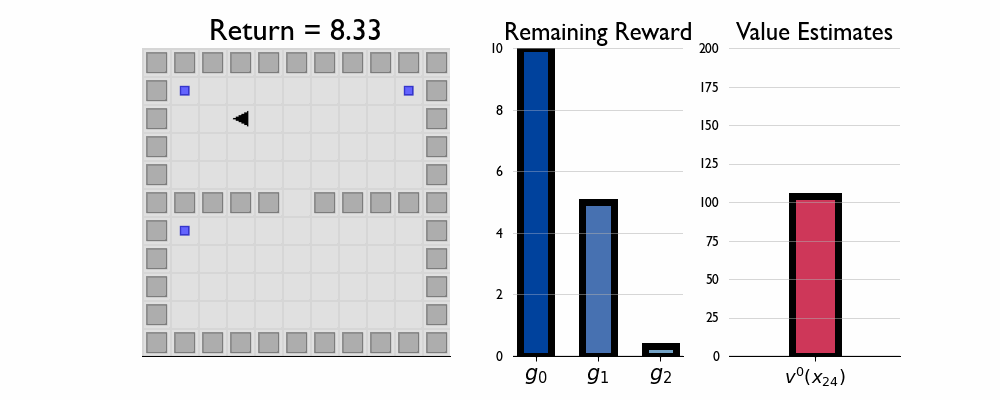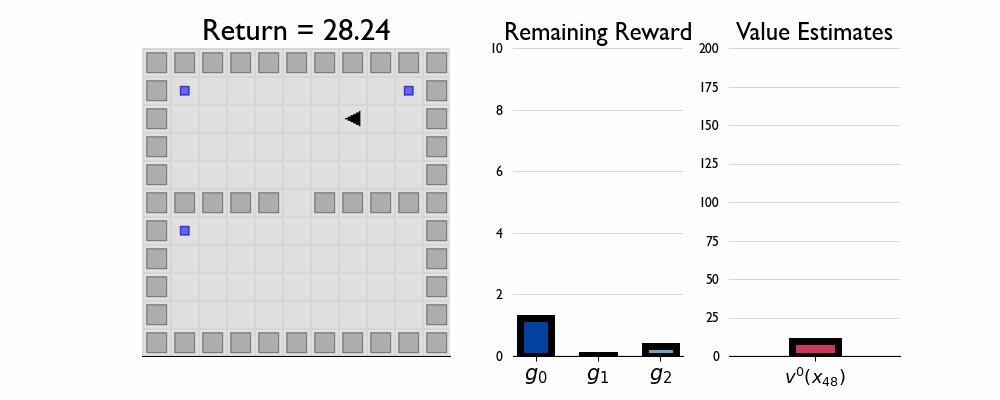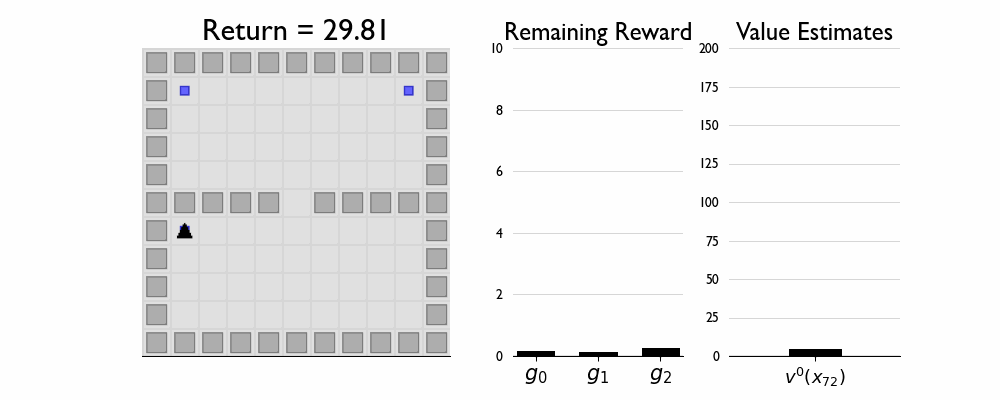
Policy Composition in FourRooms
Agent λ = 0.5:

Agent λ = 0.0:

Agent λ = 1.0:

Pixel-based agent:
![]()
Replenishing Rewards in TwoRooms